OpenSSL version 3.0.4, released on June 21th 2022, is susceptible to remote memory corruption which can be triggered trivially by an attacker. BoringSSL, LibreSSL and the OpenSSL 1.1.1 branch are not affected. Furthermore, only x64 systems with AVX512 support are affected. The bug is fixed in the repository but a new release is still pending.
Somewhat peculiarly, almost nobody is talking about this. If RCE exploitation is possible this makes it worse than Heartbleed in an isolated severity assessment, though the potential blast radius is limited by the fact that many people are still using the 1.1.1 tree rather than 3, libssl has forked into LibreSSL and BoringSSL, the vulnerability has only existed for a week (HB existed for years) and an AVX512-capable CPU is required.
This post gives some background on how this bug came to be and some notes on its exploitability.
On May 31th 2022 I found and reported an issue with constant-time Montgomery modular exponentiation in OpenSSL and BoringSSL (but not LibreSSL). For some values of B, E, M for which B ^ E % M == 0, some functions would return M instead of 0; the result was not fully reduced.
It was found that there are four distinct code paths affected by this:
David Benjamin of Google analyzed the issue extensively and found that the bug does not constitute a security risk (at least not internally; external callers might end up in incorrect states depending on what they are trying to compute). Interestingly, he also found an apparent bug in the paper by Shay Gueron upon which the RSAZ code is based.
This took my fuzzer a long time to find, because the odds of finding B ^ M % E = 0 for large, N-bit values of B, E, M where those values are semi-random are small, so I proceeded to add a modular exponentation solver, so the bug can now be found quite quickly, and hopefully it helps finding more, similar bugs in the future (in OpenSSL or elsewhere). (Z3’s performance in solving equations involving modular exponentiation is quite poor so I had to roll my own).
The fix that was applied to the dual 1024 RSAZ code is wrong because the reduction function is called with num set to the bit size, where it should be number of BN_ULONG elements (which are always 8 bytes large, because that is the size of an unsigned long on x64 systems, which is the only architecture which can have AVX512 support). So with the input sizes being 1024 bits, 8192 bytes are accessed (read from or written to) instead of 128.
On to the bug internals. There are 5 distinct arrays involved. 3 arrays are overwritten.
Variable
Description
Allocated size
Over-read/write
Total
Read/write?
res1
modexp result 1
128
896
8192
Read, then write
m1
Modulus 1
128
896
8192
Read
res2
modexp result 1
128
896
8192
Read, then write
m2
Modulus 2
128
896
8192
Read
storage
Scratch space
1184
7296
8192
Write, then read
8192 bytes are read from res1, res2, m1, m2 and storage
8192 bytes are written to res1, res2 and storage (this is where the memory corruption takes place)
If we consider res1_bn to be a bignum comprising res1[0..8192] (where the last byte is the most significant byte) and m1_bn to be m1[0..8192], then if res1_bn < m1_bn, the contents of res1[0..8192] will be left unchanged after being overwritten. The same applies for res2 and m2.
This implies that if you can set the most significant bit of m1[8191] to 1 and the most significant bit of res1[8191] to 0, then res1[0..8192] will retain its original state (and no actual corruption takes place). This circumstance may occur by chance. The same applies for res2 and m2.
Conversely, if res1_bn >= m1_bn, then after the write, res1[N] will be one of {res1[N], res1[N] - m1[N], res1[N] - m1[N] - 1}. The same applies for res2 and m2.
After the overwrites have occurred, storage[N]will be ~(m2[N] - res2[N]) or ~(m2[N] - res2[N])+1.
From this it follows that if you control m2[N]and res2[N], you mostly control storage[N].
The original contents of storage is never read, so it does not influence the end state in any way.
Summarized:
Variable
Post-write value
res1[N]
res1[N]orres1[N] - m1[n]orres1[N] - m1[N] - 1
res2[N]
res2[N]orres2[N] - m2[n]orres2[N] - m2[N] - 1
storage[N]
~(m2[N] - res2[N])or~(m2[N] - res2[N]) + 1
OpenSSL vulnerability post-write states
Each of these lemma’s are true independent of what the inputs to the modexp function are, and of any other variable or state.
The (wrapping) subtraction mechanics at play here are interesting because you can use them to apply pointer delta’s to a function pointer to make it point to a different function and this can help circumvent ASLR, because while the function addresses are randomized, their spacing is constant for every given binary.
For example, if:
a single, particular BN_ULONG in the res1 array is known to contain an active pointer to a specific function
and you can control the BN_ULONG in m1 at the same index (for example via heap spraying)
and the rest of the state is completely unknown and uncontrolled
then by setting m1[N] to oldfunc - newfunc, the original function pointer will be exactly newfunc after the overflow with a 25% probability:
void goodfunc(void) { printf("good\n"); }
void badfunc(void) { printf("bad\n"); }
int main(void)
{
/* Indices 0..127 are within allocated bounds */
/* Beyond that is either unallocated or allocated by different parts
* of the program.
*/
struct {
BN_ULONG storage[1024], res1[1024], m1[1024], res2[1024], m2[1024];
} vars;
/* Randomize everything; not known to the attacker */
FILE* fp = fopen("/dev/urandom", "rb");
assert(fread(&vars, 1, sizeof(vars), fp));
fclose(fp);
/* Assume res1[345] contains a function pointer used internally by OpenSSL */
vars.res1[345] = (BN_ULONG)(&goodfunc);
/* Assume we control m1[345] */
vars.m1[345] = (BN_ULONG)(&goodfunc) - (BN_ULONG)(&badfunc);
bn_reduce_once_in_place(vars.res1, /*carry=*/0, vars.m1, vars.storage, 1024);
bn_reduce_once_in_place(vars.res2, /*carry=*/0, vars.m2, vars.storage, 1024);
void (*fnptr)(void) = (void*)vars.res1[345];
fnptr(); /* good or bad? */
return 0;
}
OpenSSL makes heavy use of function pointers. Running find -name '.c' -exec grep 'METH. = {' {} \; | grep -v test from the repository root shows over 130 data structures that encapsulate a set of function pointers. Delta subtraction may be useful in exploiting this circumstance to make OpenSSL misbehave to varying degrees of severity.
Apart from code execution, there can also be scenario’s where private data is leaked to the attacker.
Assume:
R¹ = res[I..J]
M¹ = m[I..J]
I, K >= 128
J, L <= 1023
Let R¹ be an allocated space which the attacker can read and write (for example an internal TLS state whose value is, to an extent, determined by how the attacker conducts the handshake, and which can be read, to an extent, by how the TLS code subsequently behaves based on its state).
Let M¹ contain some kind of secret information.
Recall that the combination of res[N] (before the overwrite) and m[N] leaks into res[N]. It follows that if the attacker has read-write access to R¹, M¹ can be partially or completely inferred.
This is what I’ve deduced so far. It’s possible there are errors in this post; please e-mail guido@guidovranken.com and I’ll correct them and credit you. You can follow me on Twitter.
Larry Stefonic of wolfSSL contacted me after he’d noticed my project for fuzzing cryptographic libraries called Cryptofuzz. We agreed that I would write a Cryptofuzz module for wolfSSL.
I activated the wolfSSL module for Cryptofuzz on Google’s OSS-Fuzz, where it has been running 24/7 since. So far, Cryptofuzz has found a total of 8 bugs in wolfCrypt.
Larry and Todd Ouska then asked me if I was interested in writing fuzzers for the broader wolfSSL library. I was commissioned for 80 hours of work.
I started by implementing harnesses for the TLS server and client. Both support 5 different flavors of TLS: TLS 1, 1.1, 1.2, 1.3 and DTLS.
wolfSSL allows you to install your own IO handlers. Once these are in place, each time wolfSSL wants to either read or write some data over the network, these custom handlers are invoked, instead calling recv() and send() directly.
For fuzzing, this is ideal, because fuzzers are best suited to operate on data buffers rather than network sockets. Working with actual sockets in fuzzers is possible, but this tends to be slower and more complex than piping data in and out of the target directly using buffers.
Hence, by using wolfSSL’s IO callbacks, all actual network activity is sidestepped, and the fuzzers can interact directly with the wolfSSL code.
Emulating the network
In the write callback, I embedded some code that specifically checks the outbound data for uninitialized memory. By writing this data to /dev/null, it can be evaluated by valgrind and MemorySanitizer.
Furthermore, I ensured that my IO overloads mimic the behavior of a real network.
On a real network, a connection can be closed unexpectedly, either due to a transmission failure, a man-in-the-middle intervention or as a deliberate hangup by the peer.
It is interesting to explore the library’s behavior in the face of connection issues, as this can activate alternative code paths that normally are not traversed, so this strategy harbors the potential to find bugs that are missed otherwise.
For example, what if wolfSSL wants to read 50 bytes from a socket, but the remote peer sends only 20?
These are situations that are feasible if an attacker were to deliberately impose transfer throttling in their communication with an endpoint running wolfSSL.
Addition and subtraction have shown to pose a challenge in programming, especially when they pertain to array sizes; many buffer overflows and infinite loops in software (not wolfSSL in particular) can be traced back to off-by-one calculations and integer overflows.
Networking software like wolfSSL needs to keep a tally of completed and pending transmissions and in light of this it is a worthwhile experiment to observe what will happen when faced with uncommon socket behavior.
Finding instances of resource exhaustion
Buffer overflows are not the only kind of bug software can suffer from.
For example, it would be unfortunate if an attacker could bring down a TLS server by sending a small, crafted packet.
Fuzzing can be helpful in finding denial of service bugs. Normally, fuzzers use code coverage as a feedback signal. By instead using the branch count or the peak memory usage as a signal, the fuzzer will tend to find slow inputs (many branches taken means a long execution time) or inputs that consume a lot of memory, respectively.
Several years ago I implemented some modifications to libFuzzer which allow me to easily implement fuzzers that find denial-of-service bugs. For my engagement with wolfSSL, I applied these techniques to each fuzzer that I wrote. I ended up providing three binaries per fuzzer:
a generic one that seeks to find memory bugs, using code coverage as a signal
one that tries to find slow inputs by using the branch count as a signal
one that finds inputs resulting in excessive heap allocation
Emulating allocation failures
Using wolfSSL_SetAllocators(), wolfSSL allows you to replace its default allocation functions. This opens up interesting possibilities for finding certain bugs.
One thing I did in my custom allocator was to return an invalid pointer for a malloc() or realloc() call requesting 0 bytes. This way, if wolfSSL would try to dereference this pointer, a segmentation fault will occur.
This special code is needed because even AddressSanitizer will not detect access to a 0-byte allocated region, but it is important to test for, as such behavior can lead to real crashes on systems like OpenBSD, which intentionally return an invalid pointer from malloc(0), just like my code does.
Another possibility of implementing your own memory allocator is that it can be designed to fail sometimes.
On most desktop systems, malloc() always succeeds, but that may not be the case universally, especially not on resource-constrained systems which cannot resort to page swapping for acquiring additional memory.
Allocation failures activate code paths which are normally not accounted for by unit tests. I implemented this behavior for all fuzzers I wrote for wolfSSL.
In the TLS-specific code, 5 bugs were found.
Fuzzing auxiliary code
TLS is large and complex, and it can take fuzzers a while to traverse all its code paths, so in the interest of efficiency, I wrote several additional fuzzers specifically aimed at subsets of the library, like X509 certificate parsing (historically a wellspring of bugs across implementations), OCSP request and response handling (for which a subset of HTTP is implemented) and utility functions like base64 and base16 coders.
This approach found 9 additional bugs.
Testing the bignum library
wolfSSL comes with a bignum library that it uses for asymmetric cryptography. Because it is imperative that computations with bignums are sound, I took a project of mine called bignum-fuzzer (which has also found security bugs in other bignum libraries, like OpenSSL’s CVE-2019-1551) and appropriated it for use with wolfSSL. It is not only able to find memory bugs, but also incorrect calculation results.
I set out to test the following sub-libraries in wolfSSL:
Normal math
Single-precision math (–enable-sp)
Fastmath (–enable-fastmath)
5 instances of incorrect calculations were found. The other bugs involved invalid memory access and hangs.
wolfSSH
In addition to wolfSSL and wolfCrypt, I also spent some time looking at wolfSSH, which is the company’s SSH library offering.
In this component I uncovered 7 memory bugs, 1 memory leak and 1 crash bug.
Cryptofuzz is a project that fuzzes cryptographic libraries and compares their output in order to find implementation discrepancies. It’s quite effective and has already found a lot of bugs.
Bugs in cryptographic libraries found with Cryptofuzz
It’s been running continually on Google’s OSS-Fuzz for a while and most of the recent bugs were found by their machines.
Not all of these are security vulnerabilities, but some can be, depending on the way the API’s are used by an application, the degree to which they allow and use untrusted input, and which output they store or send.
If there had been any previous white-hat testing or fuzzing effort of the same scope and depth, these bugs would have transpired sooner, so it’s clear this project is filling a gap.
Another automated cryptography testing suite, Project Wycheproof by Google, takes a directed approach, with tailored tests mindful of cryptographic theory and historic weaknesses. Cryptofuzz is more opportunistic and generic, but more thorough in terms of raw code coverage.
Currently supported libraries are: OpenSSL, LibreSSL, BoringSSL, Crypto++, cppcrypto, some Bitcoin and Monero cryptographic code, Veracrypt cryptographic code, libgcrypt, libsodium, the Whirlpool reference implementation and small portions of Boost.
This is a modular system and the inclusion of any library is optional. Additionally, no library features are mandatory. Cryptofuzz works with whatever is available.
What it does
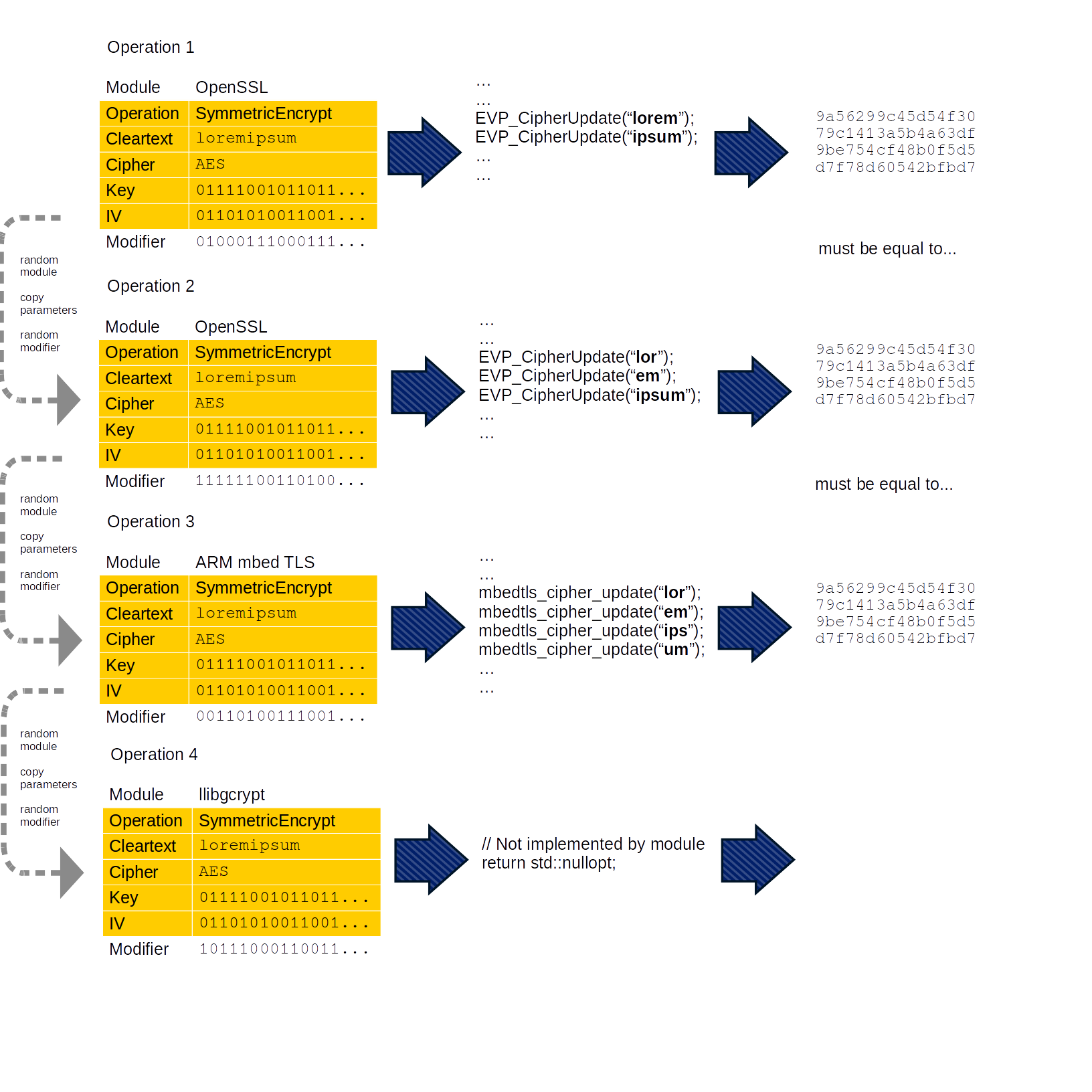
Detect memory, hang and crash bugs. Many cryptographic libraries are written in C, C++ and assembly language, which makes them susceptible to memory bugs like buffer overflows and using uninitialized memory. With the aid of sanitizers, many of these bugs become apparent. Language-agnostic programming errors like large or infinite loops and assertion failures can be detected as well. For example: Memory corruption after EVP_CIPHER_CTX_copy() with AES-GCM in BoringSSL.
Internal consistency testing. Libraries often provide multiple methods for performing a specific task. Cryptofuzz asserts that the end result is always the same irrespective of the computation method. This is a variant of differential testing. A result is not checked against another library, but asserted to be equivalent across multiple methods within the same library. For example: CHACHA20_POLY1305 different results for chunked/non-chunked updating in OpenSSL.
Multi-library differential testing. Given multiple distinct implementations of the same cryptographic primitive, and assuming that at least one is fully compliant with the canonical specification, deviations will be detected. For example: Wrong Streebog result in LibreSSL.
What it doesn’t do
It does not detect timing or other side channels, misuse of the cryptographic API and misuse of cryptography. It will also not detect bugs involving very large inputs (eg. gigabytes). Asymmetric encryption is not yet supported.
How it works
Input splitting
The fuzzing engine (libFuzzer) provides a single data buffer to work with. This is fine for simple fuzzers, but Cryptofuzz needs to extract many variables, like operation ID, operation parameters (cleartext, key, etc), module ID’s and more.
For input splitting I often use my own C++ class that allows me extract any basic type (int, bool, float, …) or more complex types easily.
The class can be instantiated with the buffer provided by the fuzzing engine.
auto a = ds.Get<uint64_t>();
auto b = ds.Get<bool>();
auto c = ds.Get<char>();
And so forth. To extract a variable number of items:
std::vector<uint8_t> v;
do {
v.push_back(ds.Get<uint8_t>());
} while ( ds.Get<bool>() == true );
Internally, the library performs length-encoded deserialization from the raw buffer into these types. As soon as it is out of data, it throws an exception, which you catch.
For more examples of this technique, see my recent fuzzers for LAME, PIEX and GFWX.
The idea multiple input data streams rather than just one, with each input type stored in its own corpus, is also prominently featured in my own fuzzer, which I hope to release as soon as I find the time for it..
Modules
The terms ‘module’ and ‘cryptographic library’ can be used interchangeably, for the most part; a module is a C++ class that is an interface for Cryptofuzz to pass data into the library code, and consume its output.
Operations
A fixed set of operations is supported. These currently include hashing (message digest), HMAC, CMAC, symmetric encryption, symmetric decryption and several KDF algorithms.
Each supported operation corresponds to a virtual function in the base class Module. A module can support an operation by overriding this function. If a module does not implement an operation, this is not a problem; Cryptofuzz is opportunistic, imposes few implementation constraints and only demands that if a result is produced, it is the correct result.
Cryptofuzz makes extensive use of std::optional. Each operation is implemented as a function that returns an optional value. This means that if a module cannot comply with a certain request, for instance when the request is “compute the SHA256 hash of the text loremipsum“, but SHA256 is not supported by the underlying library, the module can return std::nullopt.
Modifiers
A library sometimes offers multiple ways to achieve a task. Some examples:
libgcrypt optionally allows the use of ‘secure memory’ for each operation
OpenSSL offers encryption and decryption operation through the BIO and EVP interfaces
Often, libraries optionally allow in-place encryption, where cleartext and subsequent ciphertext reside at the same memory location (and the other way around for decryption)
Modifiers are buffers of data, extracted from the original input to the harness, and are passed with each operation. They allow the code to diversify internal operation handling. This is important in the interest of maximizing code coverage and increasing the odds of finding corner cases that either crash or produce an incorrect result.
By leveraging input splitting, modifiers can be used for choosing different code paths at runtime.
A practical example. Recent OpenSSL and LibreSSL can compute a HMAC with the EVP interface, or with the HMAC interface, and BoringSSL only provides the HMAC interface. This is how I branch based on the modifier and the underlying library:
Another example. A lot of the cryptographic code in OpenSSL, LibreSSL and BoringSSL is architectured around so-called contexts, which are variables (structs) holding parameters relevant to a specific operation. For example, if you want to perform encryption using the EVP interface, you’re going to have to initialize an EVP_CIPHER_CTX variable and pass it to functions like EVP_EncryptUpdate and EVP_EncryptFinal_ex.
For each type of CTX, the libraries provide copy functions. For EVP_CIPHER_CTX this is EVP_CIPHER_CTX_copy. It does what it says it does: copy over the internal parameters from one place to another, such that the copied instance is semantically identical to the source instance. But in spite of seeming trivial, this is not just an alias for memcpy; there are different handlers for different ciphers and ciphermodes and copying may require deep-copying substructures.
I created a class that abstracts creating, copying and freeing contexts. Using C++ templates and method overloading I was able to easily generate a tailored class for each type of context (EVP_MD_CTX, EVP_CIPHER_CTX, HMAC_CTX and CMAC_CTX). The class furthermore provides a GetPtr() method with which you can access a pointer to the context. (Don’t stop reading here — it will become clear 😉 ).
I instantiate the class with a reference to a Datasource, which is my input splitter. Each time I need to pass a pointer to the context to an OpenSSL function, I call GetPtr(). This extracts a bool from the input splitter, and decides whether or not to perform a copy operation.
Here’s my message digest code for the OpenSSL module:
std::optional<component::Digest> OpenSSL::OpDigest(operation::Digest& op) {
std::optional<component::Digest> ret = std::nullopt;
Datasource ds(op.modifier.GetPtr(), op.modifier.GetSize());
util::Multipart parts;
CF_EVP_MD_CTX ctx(ds);
const EVP_MD* md = nullptr;
/* Initialize */
{
parts = util::ToParts(ds, op.cleartext);
CF_CHECK_NE(md = toEVPMD(op.digestType), nullptr);
CF_CHECK_EQ(EVP_DigestInit_ex(ctx.GetPtr(), md, nullptr), 1);
}
/* Process */
for (const auto& part : parts) {
CF_CHECK_EQ(EVP_DigestUpdate(ctx.GetPtr(), part.first, part.second), 1);
}
/* Finalize */
{
unsigned int len = -1;
unsigned char md[EVP_MAX_MD_SIZE];
CF_CHECK_EQ(EVP_DigestFinal_ex(ctx.GetPtr(), md, &len), 1);
ret = component::Digest(md, len);
}
end:
return ret;
}
I instantiate CF_EVP_MD_CTX as ctx once, passing a reference to ds, near the top of the function.
Then, each time I need access to the ctx, I call ctx.GetPtr(): once as a parameter to EVP_DigestInitEx(), once to EVP_DigestUpdate() and once to EVP_DigestFinal_ex().
Each time ctx.GetPtr() is called, the actual context variable EVP_MD_CTX may or may not be copied. Whether it is copied or not depends on the modifier. The contents of the modifier is ultimately determined by the mutations performed by the fuzzing engine.
This approach is more versatile than copying the context only once, because this will catch bugs that depend on context copying at a specific place, or as part of a specific sequence, whereas copying it just once potentially comprises a narrower state space.
Input partitioning
It is common for cryptographic libraries to allow the input to be passed in steps. If you want to compute a message digest of the text “loremipsum”, there are a large amount of distinct hashing steps you could perform. For example:
Pass lorem, then ipsum
Pass lor, then em, then ipsum
Pass lor, then em, then ip, then sum.
And so forth. To test whether an input always produces the same output regardless of how it’s partitioned, all current Cryptofuzz modules will attempt to pass input in chunks where it is supported.
Helper functions are provided to pseudo-randomly partition an input based on the modifier, and implementing is often as easy as:
Datasource ds(op.modifier.GetPtr(), op.modifier.GetSize());
util::Multipart parts = util::ToParts(ds, op.cleartext);
for (const auto& part : parts) {
CF_CHECK_EQ(HashUpdate(ctx, part.first, part.second), true);
}
Operation sequences
The same operation can be executed multiple times. This is even necessary for differential testing; to discover differences between libraries, the same operation must be executed by each library before their results can be compared.
Each time the same operation is run, a new modifier for it is generated.
So we end up with a sequence of identical operations but each run by a certain module, and each with a new modifier.
Fuzzing multiple cryptographic libraries with Cryptofuzz
Once the batch of operations has been run, Cryptofuzz filters out all empty results. In the remaining set, each result must be identical. If it is not, then Cryptofuzz prints the operation parameters (cleartext, cipher, key, IV, and so on) and the result for each module, and calls abort().
Multi-module support
Modules, along with the cryptographic library that they implement, are linked statically into the fuzzer binary.
More libraries do not necessarily make it slower. Each run, Cryptofuzz picks a set of random libraries to run an operation on. Adding more libraries does not cause an increase in total operations; only a few operations will be executed each run, regardless of the total amount of modules available.
Additional tests
Each time an encryption operation succeeds, Cryptofuzz will attempt to decrypt the result using the same module. If the decryption operation either fails, or the decryption output is not equivalent to the original cleartext, a crash will be enforced.
Cryptofuzz also allows “static” tests that operate on a single result. Here is a postprocessing hook that gets called after a SymmetricEncrypt operation, and detects IV sizes larger than 12 bytes in encrypt operations with ChaCha20-Poly1305, which is a violation of the specification (see also OpenSSL CVE-2019-1543 which was not found by me but upon which I based this test).
I’ve been working on this project full-time for several months. I suppose I could seize this opportunity to say that I do this to save the planet from the apocalypse due to a signed integer overflow in OpenSSL, but I’m really just addicted to staring at fuzzer statistics ;).
It’s a lot of fun, but also a lot of work.
I’m especially interested in exploring the fringes of an API’s legal use, and this requires a close reading of the documentation, getting my implementation exactly right and if I get a crash or odd result, working out whether this is due to a fault of my own or not.
Perhaps surprisingly, writing good bug reports is a lot of work. Ideally I want to present readily compilable proof of concept code to the library maintainers so that they won’t have to get bogged down in my fuzzer’s technical details in order to understand a bug in their own code.
I’m proud of the project as it stands, and I’d love to expand it to support more very widely used libraries like Go and Java’s cryptographic code. Considering what I’ve seen so far, I’d be surprised to not find more bugs in popular cryptographic software.
Google has rewarded me $1000 for initial integration of Cryptofuzz into OSS-Fuzz, for which I’m grateful. This is all the income this project has generated so far, and I’m not complaining because it was a hobby project from the outset, but going forward I will have to forgo Cryptofuzz enhancements in pursuit of more profitable ventures, for the simple reason that I need an income and can’t spend all my time on hobby projects forever.
I submitted a grant proposal to the Core Infrastructure Initiative about one month ago. This project seems to align largely with their objectives. Unfortunately, I have not yet received a response.
If you rely on some cryptographic library (Go? Java? Rust? Javascript?) and would like to fund its integration into Cryptofuzz, please get in touch.
Edit 26 September 2019: In addition to the $1000 initial integration reward, I’ve received an additional $5000 from Google for ideal integration. A private person has also donated two $100 Amazon gift cards, which I’ve partially spent on purchasing a Raspberry Pi 4 for testing cryptographic libraries on ARM. The Core Infrastructure Initiative never responded.
Edit 24 October 2019: 35 bugs found. Someone donated $1,000 (thanks again) and I’ve submitted a grant proposal to RIPE NCC’s Community Projects Fund. I’ve been working on elliptic curve cryptography support in a separate branch and will merge this soon.
The attached document describes a new fuzz testing engine I have been busy with. As a power user of fuzzing libraries I’ve noticed some shortcomings (in my view) of the existing offers, and decided to scratch my own itch. Enjoy! PDF LINK.
I wrote a fuzzer for libsrtp for purely recreational reasons. I reported the bugs I found to the libsrtp security mailing list several months ago. Finally those bugs seem to have been fixed in the git master tree. Apparently these findings and fixes for them don’t seem to prompt a new release. Cisco has stopped responding and I don’t know what the deal is. I recently also contacted Cisco Talos but they didn’t respond at all. So I’ve decided to publish my fuzzers. I put considerable effort in it but I’m now tired of this project because nobody really seems to care, and I am abandoning it. Underwhelming experience, exception to the rule.
EDIT 23/03: Removed invalid information about Talos. My bad.
A security audit of the widely used SoftEther VPN open source VPN
client and server software [1] has uncovered 11 remote security
vulnerabilities. The audit has been commissioned by the Max Planck
Institute for Molecular Genetics [2] and performed by Guido Vranken
[3]. The issues found range from denial-of-service resulting from
memory leaks to memory corruption.
The 80 hour security audit has relied extensively on the use of
fuzzers [4], an approach that has proven its worth earlier with the
discovery of several remote vulnerabilities in OpenVPN in June of 2017
[5]. The modifications made to the SoftEther VPN source code to make
it suitable for fuzzing and original code written for this project are
open source [6]. The work will be made available to Google’s OSS-Fuzz
initiative [7] for continued protection of SoftEther VPN against
security vulnerabilities. An updated version of SoftEther VPN that
resolves all discovered security vulnerabilities is available for
download immediately [8].
In May I started building fuzzers for OpenVPN because I liked engaging in the challenge of finding more vulnerabilities after two fresh audits. I never intended or expected to receive money for this. In addition to the money donated by people and companies to my Bitcoin address (thank you very much again), OSTIF reached out to me and offered to reward me with a bounty of $5000 for the vulnerabilities and for completing the fuzzers. Thank you so much!
The fuzzers can be found here: https://github.com/guidovranken/openvpn/tree/fuzzing There are still some small portions of code that remain un-fuzzed. I am very busy with contracting work so I won’t be working on it sometime soon. You are welcome to extend it and find more vulnerabilities, and you might be eligible for bounties yourself.
OSTIF is currently running a fundraiser to get OpenSSL 1.1.1 audited. Check it out and spread the word.
This concerns a remote buffer overflow vulnerability in OpenVPN. It has been fixed in OpenVPN 2.4.4 and 2.3.18. It is suspected that only a small number of users is vulnerable to this issue, because it requires having explicitly enabled the outdated ‘key method 1’.
I expect them to be merged into the main project soon.
So far only one issue has been found: https://github.com/bitcoin/bitcoin/pull/11081 . This code is currently unused and does not pose a security risk (forks of Bitcoin may want to check whether they are using it).
Judging by the number of issues found (1) after extensive fuzzing, the Bitcoin code appears to be exceptionally well-written. Which is also exceptionally good news, because this code is not only used by Bitcoin but also by many, many altcoins, and thus guards billions and billions of dollars.
I’m actively working on expanding the fuzzers and their code coverage (as much as time permits).
Tip jar: 1BnLyXN2QwdMZLZTNqKqY48bU4hN2A3MwZ
In other news, I have a new OpenVPN vulnerability coming up that’s the worst yet in terms of severity but only affects a small number of users. To be announced.
“FreeRADIUS is the most widely deployed RADIUS server in the world. It is the basis for multiple commercial offerings. It supplies the AAA needs of many Fortune-500 companies and Tier 1 ISPs.” (http://freeradius.org)
FreeRADIUS asked me to fuzz their DHCP and RADIUS packet parsers in version 3.0.x (stable branch) and version 2.2.x (EOL, but receives security updates). 11 distinct issues that can be triggered remotely were found.
“There are about as many issues disclosed in this page as in the previous ten years combined.”
v2, v3: CVE-2017-10978. No remote code execution is possible. A denial of service is possible.
v2: CVE-2017-10979. Remote code execution is possible. A denial of service is possible.
v2: CVE-2017-10980. No remote code execution is possible. A denial of service is possible.
v2: CVE-2017-10981. No remote code execution is possible. A denial of service is possible.
v2: CVE-2017-10982. No remote code execution is possible. A denial of service is possible.
v2, v3: CVE-2017-10983. No remote code execution is possible. A denial of service is possible.
v3: CVE-2017-10984. Remote code execution is possible. A denial of service is possible.
v3: CVE-2017-10985. No remote code execution is possible. A denial of service is possible.
v3: CVE-2017-10986. No remote code execution is possible. A denial of service is possible.
v3: CVE-2017-10987. No remote code execution is possible. A denial of service is possible.
v3: CVE-2017-10988. No remote code execution is possible. No denial of service is possible. Exploitation does not cross a privilege boundary in a correct and realistic product deployment.
Contact me if
you are a vendor of a (open source) C/C++ application and want to eliminate security issues in your product
you or your company relies on an (open source) C/C++ application and want ensure that it is secure to use
you’d like to organize a crowdfunding campaign to eliminate security issues in an open source C/C++ application for the benefit of all who rely on it